Σημειωματάριο Τετάρτης 6 Δεκ. 2017¶
Επεξεργασία δεδομένων από ένα αρχείο μαθημάτων του Τμήματος¶
Σήμερα δουλέψαμε πάνω σε ένα αρχείο τύπου .csv (comma separated values) στο οποίο υπήρχαν τα μαθήματα που έχουν περάσει όλοι οι φοιτητές του Τμήματος (που είναι ακόμη στο Τμήμα). Τα ονόματα και οι αριθμοί μητρώου των φοιτητών είχαν αντικατασταθεί από τυχαίους αριθμούς ώστε να διατηρείται η ανωνυμία.
Είδαμε κατ' αρχήν το πώς χρησιμοποιούμε το python module csv για να διαβάζουμε (και να γράφουμε, αν και δεν το κάναμε αυτό) αρχεία τύπου .csv.
Αφού ανοίξουμε το αρχείο με το συνηθισμένο τρόπο για διάβασμα (στη μεταβλητή f, π.χ.) καλούμε μετά τη συνάρτηση csv.reader (στην οποία δηλώνουμε ποιος είναι ο διαχωριστικός χαρακτήρας στο αρχείο και ποιος ο χαρακτήρας quote (κόμμα και διπλά εισαγωγικά αντίστοιχα στην περίπτωσή μας) και η συνάρτηση αυτή επιστρέφει ένα αντικείμενο, σα λίστα, την οποία μπορούμε να διανύσουμε με ένα απλό for loop και διανύοντάς το παίρνουμε σε μια λίστα κάθε φορά τα πεδία (αυτά που διαχωρίζονται με το κόμμα) κάθε γραμμής.
Έχουμε ονοματίσει συμβολικά τις διάφορες στήλες του αρχείου ώστε να χρησιμοποιούμε κάποιες επεξηγηματικές λέξεις για να αναφερόμαστε σε αυτά αντί για αριθμούς. Οι στήλες του αρχείου είναι οι
AM=0; NAME=1; STATUS=2; COURSEINTNUMBER=3; COURSENUMBER=4; COURSENAME=5;
DEPTNUMBER=6; DEPTNAME=7; YEAR=8; SEMESTER=9; UNITS=10; ECTS=11; GRADE=12;
Μερικές από τις γραμμές του αρχείου αυτού μοιάζουν κάπως έτσι:
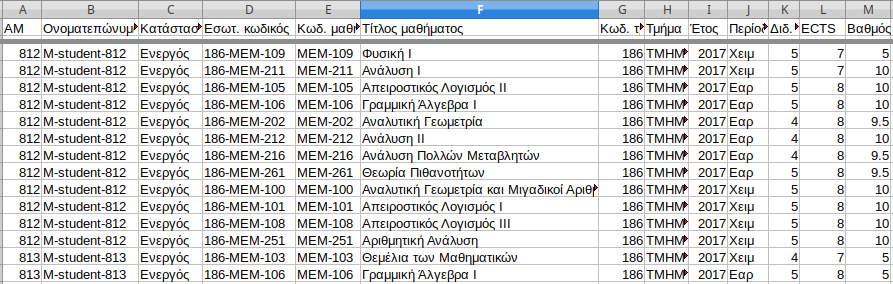
Στο πρώτο μας πρόγραμμα σκοπό έχουμε να βρούμε τον αριθμό των φοιτητών που αναφέρονται σε αυτό το αρχείο. Βάζουμε όλους τους αριθμούς μητρώου (όχι τους πραγματικούς, αλλά και πάλι μοναδικούς) στη λίστα allam μόνο μια φορά τον καθένα και στο τέλος βρίσκουμε το μήκος της λίστας.
import csv
AM=0; NAME=1; STATUS=2; COURSEINTNUMBER=3; COURSENUMBER=4; COURSENAME=5;
DEPTNUMBER=6; DEPTNAME=7; YEAR=8; SEMESTER=9; UNITS=10; ECTS=11; GRADE=12;
allam = [] # εδώ θα μπουν όλοι οι αριθμοί μητρώου, μόνο μια φορά ο καθένας
f = open("courses-anon.csv", "r")
reader = csv.reader(f, delimiter=',', quotechar='"')
firstrow=True # θέλουμε να πετάξουμε την πρώτη γραμμή του αρχείου (επικεφαλίδες)
for row in reader:
if firstrow: # αυτό το if θα πιάσει μόνο την πρώτη φορά που θα μπούμε στο loop
firstrow=False
continue
if row[AM] not in allam: # αν δεν έχουμε ξαναδεί τον φοιτητή αυτό πριν
allam.append(row[AM]) # τον προσθέτουμε στη λίστα όλων των ΑΜ (allam)
f.close()
print("Αριθμός φοιτητών: ", len(allam))
Στο επόμενο μετράμε τον αριθμό των διαφορετικών μαθημάτων που έχουν δοθεί (διαφορετικοί κωδικοί μαθημάτων). Επειδή η διαδικασία είναι ίδια με το μέτρημα των φοιτητών φτιάχνουμε μια συνάρτηση που αυτό που κάνει είναι να μας πει πόες μοναδικές τιμές υπάρχουν σε μια στήλη του αρχείου. Με τη στήλ AM μετράμε τους φοιτητές και με τη στήλη COURSENUMBER μετράμε τα διαφορετικά μαθήματα.
import csv
AM=0; NAME=1; STATUS=2; COURSEINTNUMBER=3; COURSENUMBER=4; COURSENAME=5;
DEPTNUMBER=6; DEPTNAME=7; YEAR=8; SEMESTER=9; UNITS=10; ECTS=11; GRADE=12;
def countdifferent(col): # Επιστρέφει το πόσες διαφορετικές τιμές υπάρχουν στη στήλη col
L = []
f = open("courses-anon.csv", "r")
reader = csv.reader(f, delimiter=',', quotechar='"')
firstrow = True
for row in reader:
if firstrow:
firstrow=False; continue
if row[col] not in L:
L.append(row[col])
f.close()
return len(L)
print("Αριθμός φοιτητών: ", countdifferent(AM))
print("Αριθμός μαθημάτων: ", countdifferent(COURSENUMBER))
Στο επόμενο μετράμε διάφορα πράγματα.
Σε ένα πέρασμα του αρχείου κρατάμε διάφορες πληροφορίες, κατά κανόνα σε λεξικά.
Στο λεξικό courseinfo κρατάμε, με κλειδί κάθε κωδικό μαθήματος, μια λίστα με τις φορές που δόθηκε αυτό το μάθημα. Μια φορά καθορίζεται από το έτος (ημερολογιακό) και το εξάμηνο (εαρινό ή χειμερινό) που το μάθημα αυτό δόθηκε. Έτσι τα στοιχεία της λίστας του κάθε μαθήματος στο λεξικό courseinfo είναι λίστες-ζεύγη με πρώτο στοιχείο το έτος και δεύτερο στοιχείο το εξάμηνο που το μάθημα αυτό δόθηκε. Τυπώνοντας στο τέλος τους κωδικούς μαθήματος (με φθίνουσα σειρά φορών που αυτά δόθηκαν) και το πόσες φορές αυτά δόθηκαν παίρνουμε τις παρακάτω πρώτες γραμμές (υπάρχουν πολύ περισσότερες):
Το ΜΑΘ-102 (τιτλος: Απειροστικός Λογισμός I) έχει δοθεί 28 φορές
Το ΜΑΘ-151 (τιτλος: Αγγλικά II) έχει δοθεί 24 φορές
Το ΜΑΘ-106 (τιτλος: Γλώσσα Προγραμματισμού) έχει δοθεί 22 φορές
Το ΜΑΘ-152 (τιτλος: Αγγλικά III) έχει δοθεί 21 φορές
Το ΜΑΘ-103 (τιτλος: Απειροστικός Λογισμός II) έχει δοθεί 21 φορές
Το ΜΑΘ-150 (τιτλος: Αγγλικά I) έχει δοθεί 20 φορές
Το ΜΑΘ-110 (τιτλος: Άλγεβρα) έχει δοθεί 20 φορές
Το ΜΑΘ-100 (τιτλος: Γενικά Μαθηματικά) έχει δοθεί 20 φορές
Το ΜΑΘ-101 (τιτλος: Εισαγωγή στη Θεωρία Συνόλων) έχει δοθεί 20 φορές
Το ΜΑΘ-107 (τιτλος: Φυσική Ι) έχει δοθεί 17 φορές
Το ΜΑΘ-105 (τιτλος: Γραμμική Άλγεβρα Ι) έχει δοθεί 17 φορές
Το ΜΑΘ-108 (τιτλος: Εισαγωγή στην Ανάλυση I) έχει δοθεί 17 φορές
import csv
AM=0; NAME=1; STATUS=2; COURSEINTNUMBER=3; COURSENUMBER=4; COURSENAME=5;
DEPTNUMBER=6; DEPTNAME=7; YEAR=8; SEMESTER=9; UNITS=10; ECTS=11; GRADE=12;
courseinfo={} # με κλειδιά τους κωδικούς μαθημάτων κρατάμε το πότε δόθηκαν
coursetitle={} # με κλειδιά τους κωδικούς μαθημάτων κρατάμε τον τίτλο του μαθήματος και τα ECTS του
student={} # με κλειδιά τους ΑΜ φοιτητών κρατάμε διάφορες πληροφορίες ανά φοιτητή: ποια μαθήματα έχει περάσει,
# ποια τα συνολικά του ECTS και ποιο το άθροισμα των βαθμών του
f=open("courses-anon.csv", "r")
reader = csv.reader(f, delimiter=',', quotechar='"')
firstrow = True
for row in reader:
if firstrow:
firstrow=False; continue
am = row[AM] # σε αυτή και τις επόμενες γραμμές κρατάμε σε μεταβλητές κάποιες από τις στήλες
c = row[COURSENUMBER]
y = row[YEAR]
s = row[SEMESTER]
t = row[COURSENAME]
e = row[ECTS]
g = row[GRADE]
if c not in courseinfo.keys(): # βάζουμε σε κάθε μάθημα το πότε δόθηκε
courseinfo[c] = [ [y, s] ]
else:
if [y, s] not in courseinfo[c]:
courseinfo[c].append( [y, s] )
if c not in coursetitle.keys(): # σε κάθε μάθημα προσθέτουμε τον τίτλο του και τα ECTS του
coursetitle[c]={"title": t, "ects": e}
if am not in student.keys(): # για κάθε φοιτητή κρατάμε τα μαθήματά του, τα συνολικά ECTS του και το άθροισμα
# των βαθμών του
student[am] = {"courses":[c], "ects": float(e), "totalgrade": float(g)}
else:
student[am]["courses"].append(c)
student[am]["ects"] += float(e) # βαθμοί και ECTS πρέπει να μετατραπούν σε floats
student[am]["totalgrade"] += float(g)
f.close()
for c in courseinfo.keys(): # για κάθε κωδικό μαθήματος ταξινομούμε τις φορές που δόθηκε χρονολογικά
courseinfo[c].sort(key=(lambda x: x[0]+x[1]))
allcourses=list(courseinfo.keys()) # όλοι οι κωδικοί μαθημάτων
allcourses.sort(key=lambda x: len(courseinfo[x]), reverse=True) # ταξινομούμε με βάση το πόσες φορές δόθηκε
count=0 # για να τυπώσουμε μόνο μερικούς από τους φοιτητές
for am in sorted(list(student.keys()), # οι φοιτητές με φθίνουσα σειρά μέσου όρου (βαθμολογίας)
key=lambda x:student[x]["totalgrade"]/len(student[x]["courses"]), reverse=True):
print("Ο {} έχει ΜΟ {}".format(am, student[am]["totalgrade"]/len(student[am]["courses"])))
if count>20: break
count += 1